Oreilly 上的 Go CookBook 发布啦!内容比较基础,以下是阅读整理的笔记,和之前《100 Go Mistakes》 ,《Go 专家编程》 结合起来看效果更佳!
第一章: 错误处理 错误处理 Go 没有异常处理。它有错误,而不是异常。error 是一种内置类型,表示意外情况。你将创建一个错误并将其返回给调用函数,而不是抛出异常。
因此,对异常比较熟悉的人会发现 Go 中的错误处理特别繁琐。你不得不每次都检查返回的错误并单独处理,而不是在一系列语句中使用一张大网来捕捉异常。
✅解决方法
如果您正在编写函数,请返回 error 以及返回值(如果有)。如果您调用的是函数,请检查返回的错误,如果不是 nil,请相应地处理错误。
按照惯例,错误是最后一个返回值。
简化重复性错误处理 以这段代码为例,它打开一个 JSON 文件进行读取并解码为一个结构体:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 func unmarshal () (person Person) r, err := http.Get("https://swapi.dev/api/people/1" ) if err != nil { } defer r.Body.Close() data, err := io.ReadAll(r.Body) if err != nil { } err = json.Unmarshal(data, &person) if err != nil { } return }
可以看到上述代码中有三处错误处理,分别是进行 HTTP 请求时候,读取 HTTP 响应的时候,以及反序列化的时候。这些错误处理非常相似,实际上是重复的。如何解决这个问题呢?
✅解决方法
解决方法就是添加辅助函数,可以自己实现,也可以使用自带的。
方法1: 自定义错误检查的 check 辅助函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 func helperUnmarshal () (person Person) r, err := http.Get("https://swapi.dev/api/people/1" ) check(err, "Calling SW people API" ) defer r.Body.Close() data, err := io.ReadAll(r.Body) check(err, "Read JSON from response" ) err = json.Unmarshal(data, &person) check(err, "Unmarshalling" ) return } func check (err error, msg string ) if err != nil { log.Println("Error encountered:" , msg) } }
方法2: 创建一个类似于 template.Must 的 must 辅助函数
1 2 3 4 5 6 func must (param interface {}, err error) interface if err != nil { } return param }
1 2 3 4 5 6 7 func mustUnmarshal () (person Person) r := must(http.Get("https://swapi.dev/api/people/1" )).(*http.Response) defer r.Body.Close() data := must(io.ReadAll(r.Body)).([]byte ) must(nil , json.Unmarshal(data, &person)) return }
这样的代码更加简洁,但同时也使代码更加难以阅读,因此应尽量少用这种辅助函数。
创建自定义错误 我们可以使用 errors.New 函数(该函数仅使用简单字符串创建错误),也可以使用 fmt.Errorf 来进行错误的创建。
1 err := errors.New("Syntax error in the code" )
1 err := fmt.Errorf("Syntax error in the code at line %d" , line)
或者实现 error 接口。builtin 包包含内置类型、接口和函数的所有定义。其中一个接口是 error 接口。
任何结构体,只要有一个名为 Error 的方法返回字符串,就是错误。因此,如果您想定义自己的自定义错误以返回自定义错误信息,只需实现自己的结构并添加 Error 方法即可。
1 2 3 4 5 type CommsError struct {}func (m CommsError) Error () string return "An error happened during data transfer" }
当然,自己实现的时候,通常不会只覆盖 Error,您可以在自定义错误中添加字段和其他方法,以携带更多信息。
1 2 3 4 5 6 7 8 9 type SyntaxError struct { Line int Col int } func (err *SyntaxError) Error () string return fmt.Sprintf("Error at line %d, column %d" , err.Line, err.Col) }
当遇到自定义错误的时候,可以使用断言进行判断,然后进行处理
1 2 3 4 5 6 7 8 9 if err != nil { err, ok := err.(*SyntaxError) if ok { } else { } }
Wrapping 错误 在将错误作为另一个错误返回之前,您希望为收到的错误提供更多信息和上下文。这时我们就需要将错误进行包裹,然后再返回。
✅解决方法
最简单的是再次使用 fmt.Errorf,并将错误作为参数的一部分。
1 2 err1 := errors.New("Oops something happened." ) err2 := fmt.Errorf("An error was encountered - %w" , err1)
%w 参数允许我们在格式字符串中放置错误。在上面的示例中,err2 封装了 err1。但我们如何从 err2 中提取 err1 呢?errors 软件包中有一个函数 Unwrap 可以实现这一功能。
1 err := errors.Unwrap(err2)
或者,创建类似这样的自定义错误结构:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 type ConnectionError struct { Host string Port int Err error } func (err *ConnectionError) Error () string return fmt.Sprintf("Error connecting to %s at port %d" , err.Host, err.Port) } func (err *ConnectionError) Unwrap () error return err.Err }
错误检查 当我们需要检查特定错误或特定类型的错误时,我们应该使用 errors.Is 和errors.As 函数。errors.Is 函数将错误与一个值进行比较,而 errors.As 函数则检查错误是否属于特定类型。
errors.Is
errors.Is 函数本质上是一个相等检查。假设在代码库中定义了一组自定义错误:
1 var ApiErr error = errors.New("Error trying to get data from API" )
在您代码的其他地方,有一个函数会返回这个错误。
1 2 3 func connectAPI () error return ApiErr }
可以使用 errors.Is 检查返回的错误是否真的是 ApiErr:
1 2 3 4 5 6 err := connectAPI() if err != nil { if errors.Is(err, ApiErr) { } }
还可以验证 ApiErr 是否位于错误链的某处。让我们以 connect 函数为例,该函数返回一个 ConnectionError,ConnectionError Wrapping 了 ApiErr,此时我们再次使用 errors.Is(err, ApiErr) 来判断一次,也是返回 True。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 func connect () error return &ConnectionError{ Host: "localhost" , Port: 8080 , Err: ApiErr, } } err := connect() if err != nil { if errors.Is(err, ApiErr) { } }
errors.As
errors.As 函数允许我们检查特定类型的错误。
1 2 3 4 5 6 7 8 9 err := connect() if err != nil { var connErr *ConnectionError if errors.As(err, &connErr) { fmt.Println("是 ConnectionError 错误类型" ) log.Errorf("Cannot connect to host %s at port %d" , connErr.Host, connErr.Port) } }
总结:errors.Is 用户判断 error 链中是否包含指定的 error 值。errors.As 用户判断 error 链中是否有指定类型出现,如果有,则把 error 转换成该类型。更多示例,可见《Go 专家编程》
panic 创建了一个正常的函数,其中main调用A,A调用B,B调用C。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 package mainimport "fmt" func A () defer fmt.Println("defer on A" ) fmt.Println("A" ) B() fmt.Println("end of A" ) } func B () defer fmt.Println("defer on B" ) fmt.Println("B" ) C() fmt.Println("end of B" ) } func C () defer fmt.Println("defer on C" ) fmt.Println("C" ) fmt.Println("end of C" ) } func main () defer fmt.Println("defer on main" ) fmt.Println("main" ) A() fmt.Println("end of main" ) }
正常执行结果如下:
1 2 3 4 5 6 7 8 9 10 11 12 main A B C end of C defer on C end of B defer on B end of A defer on A end of main defer on main
假如我们在 C 函数的两个 fmt.Println 之间添加 panic,如下所示:
1 2 3 4 5 6 func C () defer fmt.Println("defer on C" ) fmt.Println("C" ) panic ("panic called in C" ) fmt.Println("end of C" ) }
C 会立即停止并在其作用域内执行延迟代码。之后,它冒泡到调用者 B,后者也立即停止并在其作用域内执行延迟代码,然后返回到其调用者 A。同样的情况也会发生在 A 上,它会冒泡到 main 函数,在其作用域内执行延迟代码。由于这是链的末端,因此它将打印出 panic 参数。
输出结果如下:
1 2 3 4 5 6 7 8 9 main A B C defer on C defer on B defer on A defer on main panic: panic called in C
recover panic recover 只有在 defer 中使用时才能工作。这是因为当函数调用 panic 时,除了延迟代码外,其他所有代码都将停止工作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 package mainimport "fmt" func A () defer fmt.Println("defer on A" ) fmt.Println("A" ) B() fmt.Println("end of A" ) } func B () defer dontPanic() fmt.Println("B" ) C() fmt.Println("end of B" ) } func C () defer fmt.Println("defer on C" ) fmt.Println("C" ) panic ("panic called in C" ) fmt.Println("end of C" ) } func main () defer fmt.Println("defer on main" ) fmt.Println("main" ) A() fmt.Println("end of main" ) } func dontPanic () err := recover () if err != nil { fmt.Println("panic called but everything's ok now:" , err) } else { fmt.Println("defer on B" ) } }
输出如下:1 2 3 4 5 6 7 8 9 10 main A B C defer on C panic called but everything's ok now: panic called in C end of A defer on A end of main defer on main
当 panic 在 C 中被调用时,C 中的延迟代码会启动,而不运行 C 中的其他代码,并冒泡至 B。B 停止运行其余代码,开始运行延迟代码,并调用 dontPanic。dontPanic 调用 recover, recover 返回传递给 panic 中的参数,然后运行恢复代码。
可见看到,在上述流程中,B 没有正常执行完成,但当 B 返回到 A 时,一切正常,代码的正常执行流程继续进行。
处理中断 从操作系统接收到一个中断信号(例如,用户按下ctrl-c),您希望进行清理并优雅地退出。正确方法是使用os/signal 包,使用 goroutine 监视中断。将清理代码放在 goroutine 中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 package mainimport ( "fmt" "os" "os/signal" "time" ) func main () ch := make (chan os.Signal) signal.Notify(ch, os.Interrupt) go func () <-ch fmt.Print("接收到终止信号~" ) os.Exit(0 ) }() time.Sleep(time.Second * 10 ) }
第二章: 字符串 字符串
string 是字节的只读(不可变)片段。它可以是任何字节,不需要任何编码或格式。这与其他编程语言不同,在其他编程语言中,字符串是字符序列。
一个字符可以由多个字节表示。这符合 Unicode 标准,该标准定义了一个编码点来表示编码空间中的一个值。在这种情况下,一个字符可以用多个码位来表示。
在 Go 语言中,码位也被称为符文,符文是 int32 类型的别名,就像字节是 uint8 类型的别名一样。
更多信息,可参考 100 Go Mistakes
字符串和字节的转换 字符串是字节的片段,因此可以通过类型转换直接将字符串转换为字节数组
1 2 str := "This is a simple string" bytes := []byte(str)
将字节数组转换为字符串也是通过类型转换完成的。
1 2 3 bytes := []byte {84 , 104 , 105 , 115 , 32 , 105 , 115 , 32 , 97 , 32 , 115 , 105 , 109 , 112 , 108 , 101 , 32 , 115 , 116 , 114 , 105 , 110 , 103 } str := string (bytes)
其他方式创建字符串 方式1: 直接使用 + 进行拼接
1 var str string = "The time is " + time.Now().Format(time.Kitchen) + " now."
方式2: 使用 string 软件包中的 Join 函数
1 var str string = strings.Join([]string {"The time is" , time.Now().Format(time.Kitchen), "now." }, " " )
方式3: 使用 fmt.Sprint
1 var str string = fmt.Sprint("The time is " , time.Now(), " now." )
fmt.Sprint 及其变体使用 interface{} 参数,这意味着它可以使用任何数据类型。
fmt.Sprint 的一个常用变体 fmt.Sprintf,第一个参数是格式字符串,可以在字符串的不同位置放置不同的动词格式,第二个参数是可以替换到动词中的数据值。
1 var str string = fmt.Sprintf("The time is %v now." , time.Now())
方式4: 使用 strings.Builder
1 2 3 4 5 var builder strings.Builderbuilder.WriteString("The time is " ) builder.WriteString(time.Now().Format(time.Kitchen)) builder.WriteString(" now." ) var str string = builder.String()
字符串转换为数字 1 2 i, err := strconv.Atoi("123" )
ParseFloat 函数将字符串解析为浮点数。32 表示 float32,64 表示 float64
1 f, err := strconv.ParseFloat("1.234" , 64 )
ParseBool 在解析表示布尔值的字符串时非常有用。它接受 1、t、T、TRUE、true、True、0、f、F、FALSE、false、False。
1 b, err := strconv.ParseBool("TRUE" )
当转换出错时,可以获取到相关的错误信息
1 2 3 4 5 6 7 8 9 str := "Not a number" _, err := strconv.Atoi(str) if err != nil { e := err.(*strconv.NumError) fmt.Println("Func:" , e.Func) fmt.Println("Num:" , e.Num) fmt.Println("Err:" , e.Err) fmt.Println(err) }
1 2 3 4 Func: Atoi Num: Not a number Err: invalid syntax strconv.Atoi: parsing "Not a number": invalid syntax
数字转换为字符串 1 2 str := strconv.Itoa(123 )
上述代码等价于
1 str := strconv.FormatInt(int64 (123 ), 10 )
第二个参数 10 代表十进制,我们换为 2 试试
1 str := strconv.FormatInt(int64 (123 ), 2 )
结果为 “1111011”。即将十进制的 123 转换为了二进制,并且是字符串格式。
FormatFloat 函数比 FormatInt 复杂一些。它根据格式和精度将浮点数转换为字符串
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 var v float64 = 123456.123456 var s string s = strconv.FormatFloat(v, 'f' , -1 , 64 ) fmt.Println("f (prec=-1)\t:" , s) s = strconv.FormatFloat(v, 'f' , 4 , 64 ) fmt.Println("f (prec=4)\t:" , s) s = strconv.FormatFloat(v, 'f' , 9 , 64 ) fmt.Println("f (prec=9)\t:" , s) s = strconv.FormatFloat(v, 'e' , -1 , 64 ) fmt.Println("\ne (prec=-1)\t:" , s) s = strconv.FormatFloat(v, 'E' , -1 , 64 ) fmt.Println("E (prec=-1)\t:" , s) s = strconv.FormatFloat(v, 'e' , 4 , 64 ) fmt.Println("e (prec=4)\t:" , s) s = strconv.FormatFloat(v, 'e' , 9 , 64 ) fmt.Println("e (prec=9)\t:" , s) s = strconv.FormatFloat(v, 'g' , -1 , 64 ) fmt.Println("\ng (prec=-1)\t:" , s) s = strconv.FormatFloat(v, 'G' , -1 , 64 ) fmt.Println("G (prec=-1)\t:" , s) s = strconv.FormatFloat(v, 'g' , 4 , 64 ) fmt.Println("g (prec=4)\t:" , s)
1 2 3 4 5 6 7 8 9 10 11 12 f (prec=-1) : 123456.123456 f (prec=4) : 123456.1235 f (prec=9) : 123456.123456000 e (prec=-1) : 1.23456123456e+05 E (prec=-1) : 1.23456123456E+05 e (prec=4) : 1.2346e+05 e (prec=9) : 1.234561235e+05 g (prec=-1) : 123456.123456 G (prec=-1) : 123456.123456 g (prec=4) : 1.235e+05
FormatFloat 的函数签名如下:
1 func FormatFloat (f float64 , fmt byte , prec, bitSize int ) string
参数的含义如下:
f:要转换的浮点数。fmt:格式控制字符,用于指定转换的格式。常用的格式字符有 'f'(普通浮点数格式)和 'e'(科学计数法格式)。prec:精度,表示转换后的浮点数保留的小数位数。bitSize:浮点数的位大小,表示转换的浮点数是 float32 还是 float64。常用的值为 32 和 64。
替换字符串中的字符 可以使用 strings.Replace 函数或 strings.ReplaceAll 函数替换选定的字符串。
还可以使用 strings.Replacer 类型创建替换器。
Replace && ReplaceAll
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 package mainimport ( "fmt" "strings" ) func main () var quote string = `I loved her against reason, against promise, against peace, against hope, against happiness, against all discouragement that could be.` replaced := strings.Replace(quote, "against" , "with" , 1 ) fmt.Println(replaced) replaced2 := strings.Replace(quote, "against" , "with" , 2 ) fmt.Println("\n" , replaced2) replacedAll := strings.Replace(quote, "against" , "with" , -1 ) fmt.Println("\n" , replacedAll) }
最后一次参数是替换的次数,如果 n 大于 0,则只替换前 n 个匹配的子串,如果 n 等于 0,则不进行替换;如果 n 小于 0,则替换所有匹配的子串。
ReplaceAll 相当于 Replace 将最后一个参数设置为 -1,即替换所有匹配的子串。
1 2 replacedAll2 := strings.ReplaceAll(quote, "against" , "with" ) fmt.Println("\n" , replacedAll2)
Replacer
Replacer 可让您同时进行多个替换。如果你需要进行大量替换,这就方便多了。
1 2 3 replacer := strings.NewReplacer("her" , "him" , "against" , "for" , "all" , "some" ) replaced3 := replacer.Replace(quote) fmt.Println(replaced3)
在上面的代码中,我们用 “him “替换了 “her”,用 “for “替换了 “against”,用 “some “替换了 “all”。
总结:如果是简单的替换,那么使用 Replace 更方便,如果是进行大量替换,或替换的字符比较多,那么使用 Replacer 则效率更高。
创建子串 1 2 3 var quote string = `I loved her against reason, against promise, against peace, against hope, against happiness, against all discouragement that could be.`
如果你想从引文中提取 “against reason” 这几个字,你可以这样做。
如何在不手动计算引号中字母的情况下知道单词的位置呢?
1 2 3 i := strings.Index(quote, "against reason" ) j := i + len ("against reason" ) fmt.Println(quote[i:j])
字符串是否包含子串 可以使用 strings 包中的 Contains 函数。如果要检查的字符串是后缀或前缀,也可以使用 HasSuffix 或 HasPrefix 函数。
1 2 3 var quote string = `I loved her against reason, against promise, against peace, against hope, against happiness, against all discouragement that could be.`
检查是否包含 against
1 var has bool = strings.Contains(quote, "against" )
或者,也可以使用 strings.Index,如果返回结果 < 0,则表示在字符串中没有找到子串。或者使用 Count 函数,它返回在字符串中找到子串的次数,但这通常是一个较差的替代方法。
如果想知道子串是否是字符串的前缀,可以使用 HasPrefix 函数。
1 strings.HasPrefix(quote, "I loved" )
同理,可以使用 HasSuffix 函数对后缀进行同样的处理
1 strings.HasSuffix(quote, "could be." )
切分字符串为数组 strings.Split
使用 Split 包中的 strings 函数可以分割字符串。
1 2 3 4 5 var quote string = `I loved her against reason, against promise, against peace, against hope, against happiness, against all discouragement that could be.` array := strings.Split(quote, " " )
上述的分割方法中,我们使用空格作为分隔符,但是存在一些问题,结果里面带有一些换行符。这是因为原始字符串带有换行符。这可能不是你想要的,那么我们如何才能删除换行符呢?更糟糕的是,如果有多个空格,你的数组看起来就会非常凌乱,会有很多额外的空字符串元素。
1 2 3 ["I" "loved" "her" "against" "reason," "against" "promise," "\nagainst" "peace," "against" "hope," "against" "happiness," "\nagainst" "all" "discouragement" "that" "could" "be."]
strings.Fields
这时,我们可以使用 strings.Fields 来进行处理。strings.Fields 是一个专门用于将字符串按照空白字符(包括空格、制表符和换行符等)进行分割的函数。
1 array := strings.Fields(quote)
切分结果如下:
1 2 3 ["I" "loved" "her" "against" "reason," "against" "promise," "against" "peace," "against" "hope," "against" "happiness," "against" "all" "discouragement" "that" "could" "be."]
strings.FieldsFunc
其中还是含有逗号和最后的句号,如果要根据 “,” 和空格进行拆分的话,可以自定义实现 strings.FieldsFunc 函数
1 2 3 4 5 6 7 8 f := func (c rune ) bool return unicode.IsPunct(c) || !unicode.IsLetter(c) } array := strings.FieldsFunc(quote, f) fmt.Printf("%q" , array)
切分结果如下:
1 2 3 ["I" "loved" "her" "against" "reason" "against" "promise" "against" "peace" "against" "hope" "against" "happiness" "against" "all" "discouragement" "that" "could" "be"]
strings.SplitN
如果我们只想分割前 9 个元素的字符串,并将其余元素放入单个字符串中,我们则可以使用 SplitN 函数。
1 2 array := strings.SplitN(quote, " " , 10 ) fmt.Printf("%q" , array)
1 2 ["I" "loved" "her" "against" "reason," "against" "promise," "\nagainst" "peace," "against hope, against happiness, \nagainst all discouragement that could be."]
即,切分的结果只有10个元素。
strings.SplitAfter
希望在分割字符串后保留分隔符。Go 有一个名为 SplitAfter 的函数可以做到这一点。
1 2 array := strings.SplitAfter(quote, " " ) fmt.Printf("%q" , array)
1 2 3 ["I " "loved " "her " "against " "reason, " "against " "promise, " "\nagainst " "peace, " "against " "hope, " "against " "happiness, " "\nagainst " "all " "discouragement " "that " "could " "be."]
Trimming strings Trim
Trim 函数接收一个字符串和一个 cutset(由一个或多个 Unicode 代码点组成的字符串),然后返回一个去掉所有前导和尾部代码点的字符串。
1 2 3 4 var str string = ", and that is all." var cutset string = ",. " trimmed := strings.Trim(str, cutset)
TrimRight/TrimLeft
Trim 函数同时删除尾部字符和前导字符,但如果只想删除尾部字符,可以使用 TrimRight 函数,如果只想删除前导字符,可以使用 TrimLeft 函数。
1 2 3 4 var str string = ", and that is all." var cutset string = ",. " trimmedLeft := strings.TrimLeft(str, cutset) trimmedRight := strings.TrimRight(str, cutset)
TrimPrefix/TrimSuffix
1 2 var str string = ", and that is all." trimmedPrefix := strings.TrimPrefix(str, ", and " )
1 2 var str string = ", and that is all." trimmedSuffix := strings.TrimSuffix(str, " all." )
TrimSpace
TrimSpace 可以简单地删除尾部和前部的空格,可以是换行符(\n)或制表符(\t)或回车符(\r)
1 trimmed := strings.TrimSpace("\r\n\t Hello World \t\n\r" )
TrimFunc/TrimLeftFunc/TrimRightFunc
如之前的 strings.FieldsFunc 一样,TrimFunc/TrimLeftFunc/TrimRightFunc 这三个函数支持传入自定义函数,根据返回值来确认是否删除字符。
1 2 3 4 f := func (c rune ) bool return unicode.IsPunct(c) || !unicode.IsLetter(c) } trimmed := strings.TrimFunc(str, f)
从命令行接受输入 使用 Scan 包中的 fmt 函数从标准输入读取单个字符串。
要读取由空格分隔的字符串,请在 Reader 包 os.Stdin 中使用 ReadString。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package mainimport "fmt" func main () var input string fmt.Print("Please enter a word: " ) n, err := fmt.Scan(&input) if err != nil { fmt.Println("error with user input:" , err, n) } else { fmt.Println("You entered:" , input) } }
但是这样有一个问题,那就是空格之后的输入会被截断。Scan 函数可以接收多个参数,每个参数代表一个用户输入,中间用空格隔开。
1 2 3 4 5 6 7 8 9 10 func main () var input1, input2 string fmt.Print("Please enter two words: " ) n, err := fmt.Scan(&input1, &input2) if err != nil { fmt.Println("error with user input:" , err, n) } else { fmt.Println("You entered:" , input1, "and" , input2) } }
这似乎有点局限。如果要捕获一个包含空格的字符串,该怎么办?这时我们可以创建一个 Reader,并使用 Reader 的 ReadString 方法1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 package mainimport ( "bufio" "fmt" "os" ) func main () reader := bufio.NewReader(os.Stdin) fmt.Print("请输入内容:" ) readString, err := reader.ReadString('\n' ) if err != nil { fmt.Println("输入错误:" , err) } else { fmt.Println("你的输入是: " , readString) } }
转义 HTML 字符串 使用 html 包中的 EscapeString 和 UnescapeString 函数转义或取消转义 HTML 字符串。
1 2 3 str := "<b>Rock & Roll</b>" escaped := html.EscapeString(str)
1 2 unescaped := html.UnescapeString(escaped)
正则表达式 使用 regex 包,并使用 Compile 函数解析正则表达式,返回一个 Regexp 结构,然后使用 Find 函数匹配模式并返回字符串。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 var quote string = `I loved her against reason, against promise, against peace, against hope, against happiness, against all discouragement that could be.` re, err := regexp.Compile(`against [\w]+` ) re.MatchString(quote) str := re.FindString(quote) strs := re.FindAllString(quote, -1 ) locs := re.FindStringIndex(quote) quote[locs[0 ]:locs[1 ]] allLocs := re.FindAllStringIndex(quote, -1 ) replaced = re.ReplaceAllStringFunc(quote, strings.ToUpper) f := func (in string ) string split := strings.Split(in, " " ) split[1 ] = strings.ToUpper(split[1 ]) return strings.Join(split, " " ) } replaced = re.ReplaceAllStringFunc(quote, f)
总结:在诸多匹配方法中
不带 All 的函数只会返回第一个匹配项
带 All 的函数则有可能返回字符串中的所有匹配项,具体取决于第二个参数 n
带 String 的将返回字符串或字符串片段,而不带的将返回字节数组
带有 Index 的会返回匹配的索引
第三章:日志 写入日志 log.Println
1 2 3 4 5 6 7 8 func main () str := "abcdefghi" num, err := strconv.ParseInt(str, 10 , 64 ) if err != nil { log.Println("Cannot parse string:" , err) } fmt.Println("Number is" , num) }
1 2 3 4 % go run main.go 2022/01/23 18:39:06 Cannot parse string: strconv.ParseInt: parsing "abcdefghi": invalid syntax Number is 0
打印日志后,程序并没有停止,而是继续执行到程序的最后语句。它与 fmt.Println 有什么不同?其实没有区别,它在行中添加的唯一内容就是日期。
log.Fatalln
1 2 3 4 5 6 7 8 func main () str := "abcdefghi" num, err := strconv.ParseInt(str, 10 , 64 ) if err != nil { log.Fatalln("Cannot parse string" , err) } fmt.Println("Number is" , num) }
1 2 3 4 % go run main.go 2022/01/23 18:42:10 Cannot parse string strconv.ParseInt: parsing "abcdefghi": invalid syntax exit status 1
注意最后一条语句没有执行,程序以退出代码 1 结束。退出代码 1 是一般错误的总括,意思是程序出了问题,所以必须退出。
log.Panicln
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 package mainimport ( "fmt" "log" "strconv" ) func main () str := "abcdefghi" num := conv(str) fmt.Println("Number is" , num) } func conv (str string ) (num int64 ) defer fmt.Println("deferred code in function conv" ) num, err := strconv.ParseInt(str, 10 , 64 ) if err != nil { log.Panicln("Cannot parse string" , err) } fmt.Println("end of function conv" ) return }
1 2 3 2023/10/25 15:48:57 Cannot parse string strconv.ParseInt: parsing "abcdefghi": invalid syntax deferred code in function conv panic: Cannot parse string strconv.ParseInt: parsing "abcdefghi": invalid syntax
添加日志记录的字段 标准日志记录器的默认行为是在每行日志中添加日期和时间字段。但我们可以使用 SetFlags 函数为每行日志设置标志和添加字段。
可添加的字段有:Date(当地时区的日期),Time(当时时区的时间),Microseconds(微秒),UTC(如果设置了日期或者时间,则使用 UTC 时区而不是本地时区),Longfile(完整的文件名和行号),Shortfile(文件名和行号),Message prefix position(信息前缀位置)
1 2 3 4 5 6 7 8 9 10 11 log.SetFlags(log.Ldate) log.Println("Some event happened" ) log.SetFlags(log.Ldate | log.Lmicroseconds) log.Println("Some event happened" ) log.SetFlags(log.Ldate | log.Lshortfile) log.Println("Some event happened" )
将日志写入到文件 使用 SetOutput 函数将日志设置为写入文件
1 2 3 4 5 6 7 8 9 10 11 12 file, err := os.OpenFile("app.log" , os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0644 ) if err != nil { log.Fatal(err) } defer file.Close()log.SetOutput(file) log.Println("Some event happened" )
同时将文件写入到文件和标准输出
1 2 3 4 5 6 7 8 9 file, err := os.OpenFile("app.log" , os.O_APPEND|os.O_CREATE|os.O_WRONLY, 0644 ) if err != nil { log.Fatal(err) } defer file.Close()writer := io.MultiWriter(os.Stderr, file) log.SetOutput(writer) log.Println("Some event happened" ) log.Println("Another event happened" )
设置日志级别 解决方法是使用 New 函数创建一个日志记录器,这样就可以为每一个日志记录器设置日志级别。
日志级别从高到低:Fatal > Error > Warn > Info > Debug
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 package mainimport ( "log" "os" ) var ( info *log.Logger debug *log.Logger ) func init () info = log.New(os.Stderr, "INFO\t" , log.LstdFlags) debug = log.New(os.Stderr, "DEBUG\t" , log.LstdFlags) } func main () info.Println("Some informational event happened" ) debug.Println("Some debugging event happened" ) }
1 2 INFO 2022/01/26 00:53:03 Some informational event happened DEBUG 2022/01/26 00:53:03 Some debugging event happened
在基于 Unix 的系统中,我们使用 grep 命令来查看特定日志等级的日志,例如有以下日志文件:
1 2 3 4 5 DEBUG 2023/01/06 00:21:32 Some debugging event happened INFO 2023/01/06 00:21:35 Another informational event happened WARN 2023/01/06 00:23:35 A warning event happened WARN 2023/01/06 00:33:11 Another warning event happened ERROR 2023/01/06 00:33:11 An error event happened
1 2 grep "^ERROR" logfile.log // 只查看以 ERROR 开头的行 grep -v "^DEBUG" logfile.log // 查看除 Debug 之外的行
第四章:函数 函数接受多种数据类型 我们可以使用泛型来定义一个可以接受多个类型参数的函数。
Go 使用一种称为类型参数的机制来实现泛型。
类型参数是定义在函数名和参数列表之间、方括号内的抽象数据类型。
类型约束是类型参数必须满足的要求。
类型约束是一种特殊的接口。
1 2 3 4 func Add [T int | float64 ] (x T) T a + b }
甚至可以通过 | 操作符,创建一个类型结合体,从而创建一个同时允许 int 和 float64 类型的类型约束
1 2 3 type Number interface { int | float64 }
Go 还在实验包下提供了一个名为 constraints 的包,其中提供了一些常用的类型约束接口。
1 2 3 4 5 6 7 type Signed interface { ~int | ~int8 | ~int16 | ~int32 | ~int64 } type Ordered interface { Integer | Float | ~string }
有了这些,我们可以重写上述示例:
1 2 3 4 5 6 7 8 9 import "golang.org/x/exp/constraints" type Number interface { constraints.Integer | constraints.Float } func AddNumbers [T Number ](a, b T) T return a + b }
接收不同数量的参数 可变参数是一种允许任意数量参数的函数:
1 2 3 4 5 6 func varFunc (str ...string ) for _, s := range str { fmt.Printf("%s " , s) } fmt.Println() }
可以向函数传递零个或多个字符串
1 2 3 varFunc("the", "quick") varFunc("the", "quick", "brown", "fox") varFunc()
如果您已经有了一个切片,并希望将其传递给一个可变参数的函数,可以这样做:
1 2 str := []string {"the" , "quick" , "brown" , "fox" } varFunc(str...)
除了可变参数外,还可以有其他参数,不过,可变参数必须是列表中的最后一个参数
1 2 3 4 5 6 func varFunc2 (i int , str ...string ) for _, s := range str { fmt.Printf("%s " , s) } fmt.Println() }
接收任何类型的数据 使用 any 类型约束或空接口 interface{}
1 2 3 func anyFunc (a any) fmt.Printf("value is %v\n" , a) }
我们可以用不同的数据类型来调用函数
1 2 3 4 5 anyFuncReflect("hello world") anyFuncReflect(123) anyFuncReflect(123.456) anyFuncReflect(snowy) anyFuncReflect([]int{1, 2, 3})
但是有一点需要注意,因为参数是任何类型,所以函数一般不能做任何事情,换句话说,你需要知道参数是什么类型之后才能做具体的操作。
庆幸的是在 Go 中,reflect 软件包提供了两种方法来帮助您确定变量的类型。第一种是 reflect.TypeOf,它会告诉你变量的类型;第二种是 Kind,它会告诉你变量的种类。对于原始类型来说,这两个字符串是相同的。
1 2 3 func anyFuncReflect (a any) fmt.Printf("value is %v, type is %v, kind is %v\n" , a, reflect.TypeOf(a),reflect.TypeOf(a).Kind()) }
value is hello world, type is string , kind is string int , kind is int float64 , kind is float64 functions.Dog , kind is struct []int , kind is slice
对于结构体,类型是结构体名称,种类是结构体。对于整数片段,类型是 []int,种类是 slice。
即使你现在知道了它是什么,但仍然无法使用它。这是因为从 Go 的角度来看,该参数仍然是 any。要使用参数 a,需要对其进行类型断言
1 2 3 4 5 6 7 8 func anyFuncAssert (a any) dog, ok := a.(Dog) if ok { fmt.Printf("Name is %s, age is %d, breed is %s\n" , dog.Name,dog.Age,dog.Breed) } else { fmt.Println("Not a dog" ) } }
在断言中可以使用逗号、ok 模式。该模式会返回一个布尔值(在一个通常名为 ok 的变量中)和断言的类型。如果断言正确,ok 将为真;反之,则为假。
创建匿名函数 1 2 3 4 5 6 7 8 func anonFunc1 () anon := func (a, b int ) (c int ) return a + b } fmt.Println("type is:" , reflect.TypeOf(anon), "\nkind is:" , reflect.TypeOf(anon).Kind()) fmt.Println(anon(1 , 2 )) }
或者直接将参数放在函数本身后面,直接调用函数
1 2 3 4 5 6 func anonFunc2 () anon := func (a, b int ) (c int ) return a + b }(1 , 2 ) fmt.Println(anon) }
调用后保持状态的函数 如果想创建一个在执行结束后仍能保留其状态的函数,那么就应该使用闭包。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 func outerFunc () func () int count := 0 return func () int count++ return count } } next := outerFunc() fmt.Println(next()) fmt.Println(next()) fmt.Println(next())
输入输出 从输入端读取数据 可以使用 io.Reader 界面读取输入信息
Go 使用 io.Reader 接口来表示从输入数据流中读取数据的能力。任何实现了 Read 函数的结构体都是 Reader。
1 2 3 type Reader interface { Read(p []byte ) (n int , err error) }
还可以使用 strings.NewReader 函数从字符串创建一个 Reader
1 2 str := “My String Data” reader := strings.NewReader(str)
输出数据 使用 io.Writer 接口写入输出。Go 也提供了 Writer 接口
1 2 3 type Writer interface { Write(p []byte ) (n int , err error) }
Go 中的一种常见模式是函数将写入器作为参数。例如,函数会调用写入器上的 Write 函数,之后就可以从写入器中提取数据
1 2 3 var buf bytes.Bufferfmt.Fprintf(&buf, "Hello %s" , "World" ) s := buf.String()
bytes.Buffer 结构是一个 Writer 结构(它实现了 Write 函数)。(它实现了 Write 函数),因此您可以轻松创建一个并将其传递给 fmt.Fprintf 函数,该函数的第一个参数是 io.Writer。fmt.Fprintf函数会将数据写入缓冲区,稍后即可从中提取数据。
使用写入器通过写入数据来传递数据,然后再提取数据,这种模式在 Go 中非常常见。标准库中的一个例子就是 HTTP 处理器中的 http.ResponseWriter。
1 2 3 func myHandler (w http.ResponseWriter, r *http.Request) w.Write([]bytes("Hello World" )) }
上述代码将向 ResponseWriter 写入数据,即代表字符串 “Hello World “的字节片段。数据存储在 ResponseWriter 实现中,并被传递到其他地方进行进一步处理,直至最终发送到浏览器。
从 Reader 复制到 Writer 可以使用 io.Copy 函数从 Reader 复制到 Writer。例如从网上下载一个文件,然后再将文件保存。
1 2 3 4 5 6 7 8 9 10 11 var url string = "http://speedtest.ftp.otenet.gr/files/test1Mb.db" func readWrite () r, err := http.Get(url) if err != nil { log.Println("Cannot get from URL" , err) } defer r.Body.Close() data, _ := io.ReadAll(r.Body) os.WriteFile("rw.data" , data, 0755 ) }
使用 http.Get 下载文件时,会得到一个 http.Response 结构,即 r。文件内容位于http.Response结构的Body变量中,而http.Response结构是一个io.ReadCloser。ReadCloser是一个将Reader和Closer分组的接口,因此您可以像对待阅读器一样对待它。您可以使用 io.ReadAll 函数从 Body 中读取数据,然后使用 os.WriteFile 将其写入文件。
对上面代码进行性能分析测试,可以得出下载 1 MB 的文件,测试只运行了一次,耗时 1.91 秒。它还占用了 5.27 MB 内存和 218 次不同的内存分配。
我们可以选择用另一种方式,使用 io.Copy 来实现:
1 2 3 4 5 6 7 8 9 10 11 12 func copy () r, err := http.Get(url) if err != nil { log.Println("Cannot get from URL" , err) } defer r.Body.Close() file, _ := os.Create("copy.data" ) defer file.Close() writer := bufio.NewWriter(file) io.Copy(writer, r.Body) writer.Flush() }
对上述代码进行性能测试,copy 函数仅耗时 1.61 秒,使用了 43.2 kB 内存,分配了 62 次内存。可以看出对内存的占用上减少了不少。
读取文本文件 一口气读取所有内容
1 2 3 4 5 data, err := os.ReadFile("data.txt" ) if err != nil { log.Println("Cannot read file:" , err) } fmt.Println(string (data))
打开文件再读取内容 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 file, err := os.Open("data.txt" ) if err != nil { log.Println("Cannot open file:" , err) } defer file.Close()stat, err := file.Stat() if err != nil { log.Println("Cannot read file stats:" , err) } data := make ([]byte , stat.Size()) bytes, err := file.Read(data) if err != nil { log.Println("Cannot read file:" , err) } fmt.Printf("Read %d bytes from file\n" , bytes) fmt.Println(string (data))
写入文本文件 一次性写入文件
给定数据后,您可以使用 os.WriteFile 一次写入文件
1 2 3 4 5 6 data := []byte ("Hello World!\n" ) err := os.WriteFile("data.txt" , data, 0644 ) if err != nil { log.Println("Cannot write to file:" , err) }
第一个参数是文件名,数据以字节数组形式存在,最后一个参数是要赋予文件的 Unix 文件权限。如果文件不存在,将创建一个新文件。如果文件存在,则会删除文件中的所有数据,并将新数据写入文件,但不会更改权限。
创建文件并写入内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 data := []byte ("Hello World!\n" ) file, err := os.Create("data.txt" ) if err != nil { log.Println("Cannot create file:" , err) } defer file.Close()bytes, err := file.Write(data) if err != nil { log.Println("Cannot write to file:" , err) } fmt.Printf("Wrote %d bytes to file\n" , bytes)
如果文件不存在,将以指定名称和模式 0666 创建一个新文件。如果文件存在,则会删除其中的所有数据。获得文件后,可以使用 Write 方法直接写入文件,并将字节数组传递给它。
使用临时文件 可以使用 os.CreateTemp 函数创建临时文件,临时文件是在程序执行任务时为临时存储数据而创建的文件。一旦任务完成,它就会被删除或复制到永久存储空间。在 Go 中,可以使用 os.CreateTemp 函数创建临时文件。之后,就可以删除它了。不同的操作系统会将临时文件存储在不同的地方。无论临时文件存放在哪里,Go 都会使用 os.TempDir 函数告诉你它的位置:
1 fmt.Println(os.TempDir())
可以在临时目录基础上继续创建子目录
1 2 3 4 5 tmpdir, err := os.MkdirTemp(os.TempDir(), "mytmpdir_*" ) if err != nil { log.Println("Cannot create temp directory:" , err) } defer os.RemoveAll(tmpdir)
回到 os.CreateTemp,我们使用 os.CreateTemp 创建实际的临时文件,并将刚刚创建的临时目录和文件名的模式字符串传递给它,其作用与临时目录相同
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 tmpfile, err := os.CreateTemp(tmpdir, "mytmp_*" ) if err != nil { log.Println("Cannot create temp file:" , err) } data := []byte ("Some random stuff for the temporary file" ) _, err = tmpfile.Write(data) if err != nil { log.Println("Cannot write to temp file:" , err) } err = tmpfile.Close() if err != nil { log.Println("Cannot close temp file:" , err) }
如果没有选择将临时文件放到一个单独的目录中(上述 os.RemoveAll(tmpdir) 删除目录即可删除所有内容),这时可以使用 os.Remove 进行删除临时文件。
1 defer os.Remove(tmpfile.Name())
CSV 读取整个 CSV 文件 使用 encoding/csv 和 csv.ReadAll 将 CSV 文件中的所有数据读入二维字符串数组。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 file, err := os.Open("users.csv" ) if err != nil { log.Println("Cannot open CSV file:" , err) } defer file.Close()reader := csv.NewReader(file) rows, err := reader.ReadAll() if err != nil { log.Println("Cannot read CSV file:" , err) }
逐行读取 CSV 文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 file, err := os.Open("users.csv" ) if err != nil { log.Println("Cannot open CSV file:" , err) } defer file.Close()reader := csv.NewReader(file) for { record, err := reader.Read() if err == io.EOF { break } if err != nil { log.Println("Cannot read CSV file:" , err) } for value := range record { fmt.Printf("%s\n" , record[value]) } }
将 CSV 数据转码为结构体 假设有一个 User 结构体
1 2 3 4 5 6 type User struct { Id int firstName string lastName string email string }
1 2 3 4 5 6 7 8 9 10 11 var users []Userfor _, row := range rows { id, _ := strconv.ParseInt(row[0 ], 0 , 0 ) user := User{Id: int (id), firstName: row[1 ], lastName: row[2 ], email: row[3 ], } users = append (users, user) }
具体来说,strconv.ParseInt 函数接受三个参数:
第一个参数 row[0] 是要转换的字符串
第二个参数 0 是用于指定字符串所表示的整数的进制。通过设置为 0,函数会根据字符串的前缀来自动判断进制,比如 0x 表示十六进制,0 表示八进制,其他情况则默认为十进制。
第三个参数 0 是用于指定要转换的整数类型的位数。通过设置为 0,函数会根据字符串的内容自动选择合适的位数,例如根据字符串的长度来决定是使用 int64 还是 int32。
但是上述代码存在一个问题,那就是文件的标头都被转换了。
移除第一行标题 1 2 3 4 5 6 7 8 9 10 11 12 13 14 file, err := os.Open("users.csv" ) if err != nil { log.Println("Cannot open CSV file:" , err) } defer file.Close()reader := csv.NewReader(file) reader.Read() rows, err := reader.ReadAll() if err != nil { log.Println("Cannot read CSV file:" , err) }
使用不同的分隔符 要读取的 CSV 文件的分隔符不是逗号。我们可以通过以下方法进行设置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 file, err := os.Open("users2.csv" ) if err != nil { log.Println("Cannot open CSV file:" , err) } defer file.Close()reader := csv.NewReader(file) reader.Comma = ';' rows, err := reader.ReadAll() if err != nil { log.Println("Cannot read CSV file:" , err) }
忽略行 如果想忽略某些行,只需将这些行注释掉即可。但是,在 CSV 中是不行的,因为注释不在标准中。不过,使用 Go encoding/csv 软件包,你可以指定一个注释符,如果把它放在行的开头,就可以忽略整行。
1 2 3 id,first_name,last_name,email 1,Sausheong,Chang,sausheong@email.com # 2,John,Doe,john@email.com
1 2 3 4 5 6 7 8 9 10 11 12 13 file, err := os.Open("users.csv" ) if err != nil { log.Println("Cannot open CSV file:" , err) } defer file.Close()reader := csv.NewReader(file) reader.Comment = '#' rows, err := reader.ReadAll() if err != nil { log.Println("Cannot read CSV file:" , err) }
数据全写入 CSV 文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 file, err := os.Create("new_users.csv" ) if err != nil { log.Println("Cannot create CSV file:" , err) } defer file.Close()data := [][]string { {"id" , "first_name" , "last_name" , "email" }, {"1" , "Sausheong" , "Chang" , "sausheong@email.com" }, {"2" , "John" , "Doe" , "john@email.com" }, } writer := csv.NewWriter(file) err = writer.WriteAll(data) if err != nil { log.Println("Cannot write to CSV file:" , err) }
数据逐行写入 CSV 文件 1 2 3 4 5 6 7 8 9 10 11 writer := csv.NewWriter(file) for _, row := range data { err = writer.Write(row) if err != nil { log.Println("Cannot write to CSV file:" , err) } } writer.Flush()
JSON json 转换为结构体 创建包含 JSON 数据的结构体,然后使用 encoding/json 包中的 Unmarshal 将数据解码到结构体中。
有一份 skywalker.json 文件,内容如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 { "name" : "Luke Skywalker" , "height" : "172" , "mass" : "77" , "hair_color" : "blond" , "skin_color" : "fair" , "eye_color" : "blue" , "birth_year" : "19BBY" , "gender" : "male" , "homeworld" : "https://swapi.dev/api/planets/1/" , "films" : [ "https://swapi.dev/api/films/1/" , "https://swapi.dev/api/films/2/" , "https://swapi.dev/api/films/3/" , "https://swapi.dev/api/films/6/" ], "species" : [], "vehicles" : [ "https://swapi.dev/api/vehicles/14/" , "https://swapi.dev/api/vehicles/30/" ], "starships" : [ "https://swapi.dev/api/starships/12/" , "https://swapi.dev/api/starships/22/" ], "created" : "2014-12-09T13:50:51.644000Z" , "edited" : "2014-12-20T21:17:56.891000Z" , "url" : "https://swapi.dev/api/people/1/" }
Person 结构体格式如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 type Person struct { Name string `json:"name"` Height string `json:"height"` Mass string `json:"mass"` HairColor string `json:"hair_color"` SkinColor string `json:"skin_color"` EyeColor string `json:"eye_color"` BirthYear string `json:"birth_year"` Gender string `json:"gender"` Homeworld string `json:"homeworld"` Films []string `json:"films"` Species []string `json:"species"` Vehicles []string `json:"vehicles"` Starships []string `json:"starships"` Created time.Time `json:"created"` Edited time.Time `json:"edited"` URL string `json:"url"` }
调用 json.Unmarshal 一次函数,即可将数据解串到结构体实例 person 中(需要创建一个 Person 结构体实例)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 func unmarshal () (person Person) file, err := os.Open("skywalker.json" ) if err != nil { log.Println("Error opening json file:" , err) } defer file.Close() data, err := io.ReadAll(file) if err != nil { log.Println("Error reading json data:" , err) } err = json.Unmarshal(data, &person) if err != nil { log.Println("Error unmarshalling json data:" , err) } return }
解析非结构化 json 数据 假如想解析一些 JSON 数据,但事先不知道 JSON 数据的结构或属性,无法构建结构体,或者值的键是动态的。那么这时候,就不能使用预定义结构体了,而是需要使用 any。
例如有以下格式的 json 数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 { "Luke Skywalker" : [ "https://swapi.dev/api/films/1/" , "https://swapi.dev/api/films/2/" , "https://swapi.dev/api/films/3/" , "https://swapi.dev/api/films/6/" ], "C-3P0" : [ "https://swapi.dev/api/films/1/" , "https://swapi.dev/api/films/2/" , "https://swapi.dev/api/films/3/" , "https://swapi.dev/api/films/4/" , "https://swapi.dev/api/films/5/" , "https://swapi.dev/api/films/6/" ], "R2D2" : [ "https://swapi.dev/api/films/1/" , "https://swapi.dev/api/films/2/" , "https://swapi.dev/api/films/3/" , "https://swapi.dev/api/films/4/" , "https://swapi.dev/api/films/5/" , "https://swapi.dev/api/films/6/" ], "Darth Vader" : [ "https://swapi.dev/api/films/1/" , "https://swapi.dev/api/films/2/" , "https://swapi.dev/api/films/3/" , "https://swapi.dev/api/films/6/" ] }
则可以这样进行解析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 func unstructured () (output map [string ]any) file, err := os.Open("unstructured.json" ) if err != nil { log.Println("Error opening json file:" , err) } defer file.Close() data, err := io.ReadAll(file) if err != nil { log.Println("Error reading json data:" , err) } err = json.Unmarshal(data, &output) if err != nil { log.Println("Error unmarshalling json data:" , err) } return }
结果就是这样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 map[string]any{ "C-3P0": []any{ "https://swapi.dev/api/films/1/", "https://swapi.dev/api/films/2/", "https://swapi.dev/api/films/3/", "https://swapi.dev/api/films/4/", "https://swapi.dev/api/films/5/", "https://swapi.dev/api/films/6/", }, "Darth Vader": []any{ "https://swapi.dev/api/films/1/", "https://swapi.dev/api/films/2/", "https://swapi.dev/api/films/3/", "https://swapi.dev/api/films/6/", }, "Luke Skywalker": []any{ "https://swapi.dev/api/films/1/", "https://swapi.dev/api/films/2/", "https://swapi.dev/api/films/3/", "https://swapi.dev/api/films/6/", }, "R2D2": []any{ "https://swapi.dev/api/films/1/", "https://swapi.dev/api/films/2/", "https://swapi.dev/api/films/3/", "https://swapi.dev/api/films/4/", "https://swapi.dev/api/films/5/", "https://swapi.dev/api/films/6/", }, }
但是在使用的时候就比较麻烦,要对值进行断言后才能使用
1 2 3 4 5 6 unstruct := unstructured() vader, ok := unstruct["Darth Vader" ].([]any) if !ok { log.Println("Cannot type assert" ) } first := vader[0 ]
解析 json 数据流 对于 JSON 文件或 API 数据,使用 Unmarshal 简单明了。但如果 API 是流式 JSON 数据,会发生什么情况呢?在这种情况下,就不能再使用 Unmarshal 了,因为 Unmarshal 需要一次性读取整个文件。取而代之的是,encoding/json 软件包为您提供了一个 Decoder 函数来处理数据。
下面是另一个 JSON 文件,它代表了一个 JSON 数据流:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 { "name": "Luke Skywalker", "height": "172", "mass": "77", "hair_color": "blond", "skin_color": "fair", "eye_color": "blue", "birth_year": "19BBY", "gender": "male" } { "name": "C-3PO", "height": "167", "mass": "75", "hair_color": "n/a", "skin_color": "gold", "eye_color": "yellow", "birth_year": "112BBY", "gender": "n/a" } { "name": "R2-D2", "height": "96", "mass": "32", "hair_color": "n/a", "skin_color": "white, blue", "eye_color": "red", "birth_year": "33BBY", "gender": "n/a" }
请注意,这不是一个 JSON 对象,而是三个连续的 JSON 对象。这不再是一个有效的 JSON 文件,但是当你读取 http.Response 结构的 Body 时,你可以得到它。如果尝试使用 Unmarshal 读取,则会出现错误:
1 Error unmarshalling json data: invalid character '{' after top-level value
但可以使用 Decoder 对其进行解码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 func decode (p chan Person) file, err := os.Open("people_stream.json" ) if err != nil { log.Println("Error opening json file:" , err) } defer file.Close() decoder := json.NewDecoder(file) for { var person Person err = decoder.Decode(&person) if err == io.EOF { break } if err != nil { log.Println("Error decoding json data:" , err) break } p <- person } close (p) } func main () p := make (chan Person) go decode(p) for { person, ok := <-p if ok { fmt.Printf("%# v\n" , pretty.Formatter(person)) } else { break } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 json.Person{ Name: "Luke Skywalker", Height: "172", Mass: "77", HairColor: "blond", SkinColor: "fair", EyeColor: "blue", BirthYear: "19BBY", Gender: "male", Homeworld: "", Films: nil, Species: nil, Vehicles: nil, Starships: nil, Created: time.Date(1, time.January, 1, 0, 0, 0, 0, time.UTC), Edited: time.Date(1, time.January, 1, 0, 0, 0, 0, time.UTC), URL: "", } json.Person{ Name: "C-3PO", Height: "167", Mass: "75", HairColor: "n/a", SkinColor: "gold", EyeColor: "yellow", BirthYear: "112BBY", Gender: "n/a", Homeworld: "", Films: nil, Species: nil, Vehicles: nil, Starships: nil, Created: time.Date(1, time.January, 1, 0, 0, 0, 0, time.UTC), Edited: time.Date(1, time.January, 1, 0, 0, 0, 0, time.UTC), URL: "", } json.Person{ Name: "R2-D2", Height: "96", Mass: "32", HairColor: "n/a", SkinColor: "white, blue", EyeColor: "red", BirthYear: "33BBY", Gender: "n/a", Homeworld: "", Films: nil, Species: nil, Vehicles: nil, Starships: nil, Created: time.Date(1, time.January, 1, 0, 0, 0, 0, time.UTC), Edited: time.Date(1, time.January, 1, 0, 0, 0, 0, time.UTC), URL: "", }
打印结果如上所示,是三个 Person 对象。那么什么时候使用 Unmarshal,什么时候使用 decode 呢?
在 Go 语言中,JSON 解码有两种常用的方式:json.Unmarshal 和 json.Decoder。它们之间的区别如下:
json.Unmarshal:这是一个简单而方便的函数,用于将 JSON 数据解码为 Go 中的数据结构。你只需要提供要解码的 JSON 字节或字符串以及一个指向目标数据结构的指针,json.Unmarshal 函数会自动将 JSON 数据解码为对应的 Go 数据类型。这个函数适用于较小的 JSON 数据,因为它会将整个 JSON 数据加载到内存中,然后进行解码。json.Decoder:这是一个更灵活和高级的 JSON 解码器。json.Decoder 允许你对 JSON 数据进行流式处理,逐个解码 JSON 值,而不需要将整个 JSON 数据加载到内存中。你可以使用 json.Decoder 的 Decode 方法来逐个解码 JSON 数据,并将解码后的值存储到相应的变量中。这个方法适用于处理大型的 JSON 数据或需要逐个解码的情况。
总结起来,json.Unmarshal 是一个简单的函数,适用于较小的 JSON 数据,而 json.Decoder 是一个更灵活和高级的解码器,适用于处理大型的 JSON 数据或需要逐个解码的情况。
结构体转换为 json 使用 json.Marshal 将数据编译成 JSON
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 func main () person := get("https://swapi.dev/api/people/14" ) data, err := json.Marshal(&person) if err != nil { log.Println("Cannot marshal person:" , err) } err = os.WriteFile("han.json" , data, 0644 ) if err != nil { log.Println("Cannot write to file" , err) } } func get (url string ) Person r, err := http.Get(url) if err != nil { log.Println("Cannot get from URL" , err) } defer r.Body.Close() data, err := os.ReadAll(r.Body) if err != nil { log.Println("Error reading json data:" , err) } var person Person json.Unmarshal(data, &person) return person }
保存到 han.json 文件后可读性不高,这时我们可以使用 MarshalIndent 将其序列化可读性更高的格式,MarshalIndent 的参数第一个是前缀,第二个是缩进。如果你想获得简洁的 JSON 输出,前缀可以是空字符串,而缩进可以是单空格
1 data, err := json.MarshalIndent(&person, "" , " " )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 { "name": "Han Solo", "height": "180", "mass": "80", "hair_color": "brown", "skin_color": "fair", "eye_color": "brown", "birth_year": "29BBY", "gender": "male", "homeworld": "https://swapi.dev/api/planets/22/", "films": [ "https://swapi.dev/api/films/1/", "https://swapi.dev/api/films/2/", "https://swapi.dev/api/films/3/" ], "species": [], "vehicles": [], "starships": [ "https://swapi.dev/api/starships/10/", "https://swapi.dev/api/starships/22/" ], "created": "2014-12-10T16:49:14.582Z", "edited": "2014-12-20T21:17:50.334Z", "url": "https://swapi.dev/api/people/14/" }
从结构体创建 json 数据流 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 func get (n int ) (person Person) r, err := http.Get("https://swapi.dev/api/people/" + strconv.Itoa(n)) if err != nil { log.Println("Cannot get from URL" , err) } defer r.Body.Close() data, err := ioutil.ReadAll(r.Body) if err != nil { log.Println("Error reading json data:" , err) } json.Unmarshal(data, &person) return } func main () encoder := json.NewEncoder(os.Stdout) for i := 1 ; i < 4 ; i++ { person := get(i) encoder.Encode(person) } }
Marshal 和 Encode 的区别,和使用场景:
json.Marshal:你只需要提供一个 Go 数据结构的值作为输入,json.Marshal 函数会自动将其转换为 JSON 格式的数据。这个函数适用于将整个数据结构转换为 JSON 的场景。json.Encoder 允许你将 Go 数据结构编码为 JSON,并将其写入输出流(如文件、网络连接等)。与 json.Marshal 不同,json.Encoder 可以将 JSON 数据流式地写入输出,而不需要将整个 JSON 数据加载到内存中。这个方法适用于处理大型的 JSON 数据或需要流式写入的情况。
忽略结构体中的字段 使用 omitempty 标记来定义结构变量,这些结构变量在 marshaling 时就可以被忽略。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 type Person struct { Name string `json:"name"` Height string `json:"height"` Mass string `json:"mass"` HairColor string `json:"hair_color"` SkinColor string `json:"skin_color"` EyeColor string `json:"eye_color"` BirthYear string `json:"birth_year"` Gender string `json:"gender"` Homeworld string `json:"homeworld"` Films []string `json:"films"` Species []string `json:"species,omitempty"` Vehicles []string `json:"vehicles,omitempty"` Starships []string `json:"starships,omitempty"` Created time.Time `json:"created"` Edited time.Time `json:"edited"` URL string `json:"url"` }
二进制 将数据编码为 gob 格式 encoding/gob软件包是一个用于编码和解码二进制格式的 Go 库。数据可以是任何东西,但对 Go 结构体尤其有用。需要注意的是,gob 是 Go 专有的二进制格式。它并不像 protobuf 或 Thrift 那样是一种广泛使用的格式。如果您对二进制数据有更复杂的使用情况,建议您使用更常用的格式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 type Meter struct { Id uint32 Voltage uint8 Current uint8 Energy uint32 Timestamp uint64 } var reading Meter = Meter{ Id: 123456 , Voltage: 229.5 , Current: 1.3 , Energy: 4321 , Timestamp: uint64 (time.Now().UnixNano()), } func write (data interface {}, filename string ) file, err := os.Create("reading" ) if err != nil { log.Println("Cannot create file:" , err) } encoder := gob.NewEncoder(file) err = encoder.Encode(data) if err != nil { log.Println("Cannot encode data to file:" , err) } }
将 gob 数据解码为结构体 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 func read (data interface {}, filename string ) file, err := os.Open("reading" ) if err != nil { log.Println("Cannot read file:" , err) } decoder := gob.NewDecoder(file) err = decoder.Decode(data) if err != nil { log.Println("Cannot decode data:" , err) } } read(&reading, "reading" )
编码 gob 比编码 JSON 更快,二者使用的内存量是一样的。解码 gob 也比解码 JSON 快得多,而且使用的内存也少得多。
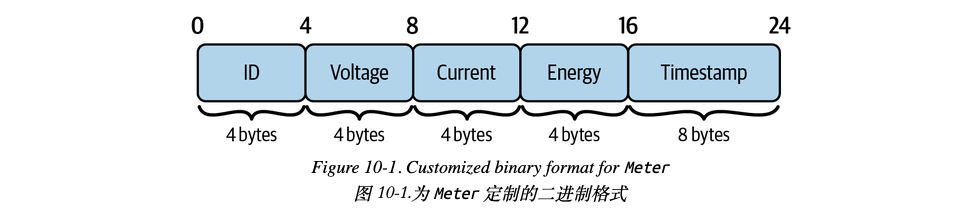
编码为定制的二进制格式 使用 gob 有几个缺点。首先,gob 仅支持 Go 语言,如果发送方和接收方都用 Go 语言编写,则效果最佳。其次,gob 保存的是整个结构,包括标签和所有内容,这使得编码后的二进制数据相对较大。事实上,在内容相同的情况下,JSON 数据的大小与 gob 数据的大小没有区别。
另一种方法是去掉标签;例如,Meter 结构可以这样存储
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package mainimport ( "encoding/binary" "log" "math" "os" "time" ) type Meter struct { Id uint32 Voltage float32 Current float32 Energy uint32 Timestamp uint64 } var reading Meter = Meter{ Id: 123456 , Voltage: 5.1 , Current: 3.2 , Energy: 4321 , Timestamp: uint64 (time.Now().UnixNano()), } func main () file, err := os.Create("data.bin" ) if err != nil { log.Println("Cannot create file:" , err) } defer file.Close() buf := make ([]byte , 24 ) binary.BigEndian.PutUint32(buf[0 :], reading.Id) binary.BigEndian.PutUint32(buf[4 :], math.Float32bits(reading.Voltage)) binary.BigEndian.PutUint32(buf[8 :], math.Float32bits(reading.Current)) binary.BigEndian.PutUint32(buf[12 :], reading.Energy) binary.BigEndian.PutUint64(buf[16 :], reading.Timestamp) file.Write(buf) }
将定制二进制解码为结构体 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 package mainimport ( "encoding/binary" "fmt" "log" "math" "os" ) type Meter struct { Id uint32 Voltage float32 Current float32 Energy uint32 Timestamp uint64 } func main () var data Meter = Meter{} file, err := os.Open("data.bin" ) if err != nil { log.Println("Cannot read file:" , err) } buf := make ([]byte , 24 ) file.Read(buf) defer file.Close() data.Id = binary.BigEndian.Uint32(buf[:4 ]) data.Voltage = math.Float32frombits(binary.BigEndian.Uint32(buf[4 :8 ])) data.Current = math.Float32frombits(binary.BigEndian.Uint32(buf[8 :12 ])) data.Energy = binary.BigEndian.Uint32(buf[12 :16 ]) data.Timestamp = binary.BigEndian.Uint64(buf[16 :]) fmt.Println(data) }
日期和时间 时间做加减法 如果想对时间做加减法,那么可以使用 Add 和 Sub 函数。
1 2 3 4 5 6 t0 := time.Now() t1 := t0.Add(10 * time.Minute) t2 := to.Add(-10 * time.Minute) t3 := t1.Sub(t2)
日期 在 time 包或标准库中都没有 Date 结构。不过,time包中有一个Date函数,用于创建特定的日期和时间,并返回一个 Time 结构体:
1 2 3 4 5 6 7 t := time.Date(2009 , time.November, 10 , 23 , 0 , 0 , 0 , time.UTC) m := t.Month() m.String() w := t.Weekday() w.String()
时区 Time 结构包含一个 Location,表示时区。创建 Location 结构有几种方法:
LoadLocation
Go 的 time 包和其他许多编程语言的库一样,使用由互联网编号分配机构(IANA)管理的时区数据库。该数据库也称作 tz 或 zoneinfo,tz数据库中的时区命名规则为 Area/Location,例如 Asia/Singapore或America/New_York。可以使用 LoadLocation(从 tz 数据库中加载位置):
1 2 3 4 5 6 7 8 9 10 func main () location, err := time.LoadLocation("Asia/Singapore" ) if err != nil { log.Println("Cannot load location:" , err) } fmt.Println("location:" , location) utcTime := time.Date(2009 , time.November, 10 , 23 , 0 , 0 , 0 , time.UTC) fmt.Println("UTC time:" , utcTime) fmt.Println("equivalent in Singapore:" , utcTime.In(location)) }
1 2 3 location: Asia/Singapore UTC time: 2009-11-10 23:00:00 +0000 UTC equivalent in Singapore: 2009-11-11 07:00:00 +0800 +08
FixedZone
创建 Location 的另一种方法是使用 FixedZone 函数。这样您就可以创建任何您想要的位置(不在 tz 数据库中),还可以随心所欲地为其命名:
摘录来自
1 2 3 4 5 6 7 func main () location := time.FixedZone("Singapore Time" , 8 *60 *60 ) fmt.Println("location:" , location) utcTime := time.Date(2009 , time.November, 10 , 23 , 0 , 0 , 0 , time.UTC) fmt.Println("UTC time:" , utcTime) fmt.Println("equivalent in Singapore:" , utcTime.In(location)) }
1 2 3 location: Singapore Time UTC time: 2009-11-10 23:00:00 +0000 UTC equivalent in Singapore: 2009-11-11 07:00:00 +0800 Singapore Time”
持续时间 想指定一个时间长度,Duration 表示时间跨度。如果您想创建 2 小时 34 分钟 5 秒的时间,该怎么办?当然是相加(因为Duration只是一个int64):
1 d := (2 * time.Hour) + (34 * time.Minute) + (5 * time.Second)
测量时间延时 Go 和许多其他编程语言一样,使用计算机中的单调时钟来测量时间。如果使用 time.Now 创建一个 Time 结构实例,并打印出该结构,就能看到单调时钟:
1 2 t := time.Now() fmt.Println(t)
1 2021-10-09 13:10:43.311791 +0800 +08 m=+0.000093742
m=+0.000093742部分是单调时钟。之前的部分是挂钟。
1 2 3 4 5 6 7 8 func main () time.Sleep(10 * time.Second) t := time.Now() fmt.Println(t) }
测量代码的运行时长
1 2 3 4 5 6 7 8 9 10 11 12 func main () time.Sleep(10 * time.Second) t1 := time.Now() t2 := time.Now() fmt.Println("t1:" , t1) fmt.Println("t2:" , t2) fmt.Println("difference:" , t2.Sub(t1)) }
AddDate、Round 和 Truncate等方法属于挂钟计算,因此它们返回的Time结构体中不会包含单调时钟。同样,In、Local 和 UTC 等返回的Time结构体也不会具有单调时钟。
如果在没有单调时钟的 Sub 结构实例上调用 Sub(或其他单调方法),会发生什么呢?
1 2 3 4 5 6 7 8 9 10 func main () t1 := time.Now().Round(0 ) t2 := time.Now().Round(0 ) fmt.Println("t1:" , t1) fmt.Println("t2:" , t2) fmt.Println("difference:" , t2.Sub(t1)) }
格式化时间 time软件包通过基于模式的布局来格式化时间。这意味着,您只需提供一个类似于参考的特定格式布局,time包就会相应地格式化时间。
1 2 3 4 5 6 7 8 func main () t := time.Now() fmt.Println(t.Format("3:04PM" )) fmt.Println(t.Format("Jan 02, 2006" )) }
还有一些 RFC 标准的 format 格式的常量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 func main () t := time.Now() fmt.Println(t.Format(time.UnixDate)) fmt.Println(t.Format(time.RFC822)) fmt.Println(t.Format(time.RFC850)) fmt.Println(t.Format(time.RFC1123)) fmt.Println(t.Format(time.RFC3339)) }
Kitchen 标准的 format 格式的常量
1 2 3 4 5 6 7 8 9 10 11 12 func main () t := time.Now() fmt.Println(t.Format(time.Stamp)) fmt.Println(t.Format(time.StampMilli)) fmt.Println(t.Format(time.StampMicro)) fmt.Println(t.Format(time.StampNano)) }
在自定义其他格式时,月必须是 1,日必须是 2,小时必须是 3,分钟必须是 4,秒必须是 5,年必须是 6,时区必须是 7
1 2 3 4 5 6 7 8 currentTime := time.Now() layout := "2006-01-02 15:04:05" formattedTime := currentTime.Format(layout)
字符串转换为 Time 结构 使用 Parse 方法将时间显示字符串转换为 Time 结构。
1 2 3 4 5 6 7 8 9 10 11 func main () str := "4:31am +0800 on Oct 1, 2021" layout := "3:04pm -0700 on Jan 2, 2006" t, err := time.Parse(layout, str) if err != nil { log.Println("Cannot parse:" , err) } fmt.Println(t.Format(time.RFC3339)) }